Setting archive group parameters
As described before, the RDB can manage multiple archive groups (for example, an archive group to store values for the "Drives" group). These archive groups contain several tables that archive the values. Alerts are stored in only one group (see Functionality of the RDB archiving for detailed information on archive groups and table structure in the RDB).
Settings for table change, backup time and others are specified per archive group. A description of the panels used to set these specific parameters is provided further on.
RDB archive group settings
Click the RDB Archive Groups button. This displays the main panel for setting the RDB archive group parameters.
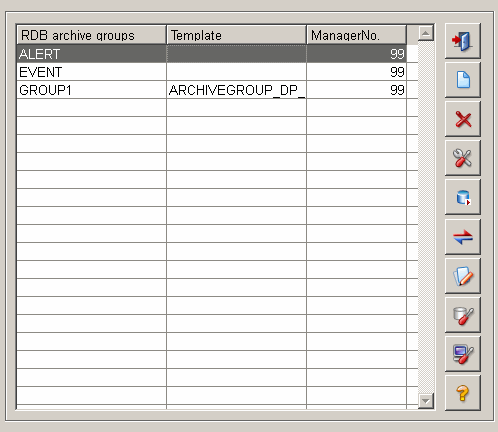
This panel displays a table of configured archive groups (the ALERT and EVENT archive groups already exist by default). The name of the archive groups and the number of the RDB Archive Manager that writes to this archive group are displayed. The template is the same as that for creating a user defined archive group (see User defined archive groups).
The other parameter panels for the RDB archive group settings are reached from this main panel. Click the New archive group
![]() button to create a new RDB archive group with the desired settings. Select a group in the table and click the Archive group
configuration
button to create a new RDB archive group with the desired settings. Select a group in the table and click the Archive group
configuration ![]() button to display a panel for editing the settings for the selected archive group (for example, automatic
backup time, maximum number of online archives). With a click on the
button to display a panel for editing the settings for the selected archive group (for example, automatic
backup time, maximum number of online archives). With a click on the ![]() button the status panel for historical synchronization of an
archive group is opened (Oracle Synchronization). This panel allows the execution of a manual synchronization, if the automatic synchronization (default) is turned off. Click
Manual backup/restore
button the status panel for historical synchronization of an
archive group is opened (Oracle Synchronization). This panel allows the execution of a manual synchronization, if the automatic synchronization (default) is turned off. Click
Manual backup/restore![]() button to start manual backup/restore and change archive for a selected archive group. The DB
config
button to start manual backup/restore and change archive for a selected archive group. The DB
config
![]() and Site config
and Site config
![]() buttons display panels for database specific configurations that only advanced database users should edit.
buttons display panels for database specific configurations that only advanced database users should edit.
The Delete![]() button removes a selected archive group from the table.
button removes a selected archive group from the table.
If the Oracle standard version is used, the number of archives may not exceed the number of maximum possible table spaces (at the moment approximately 65000)!
New
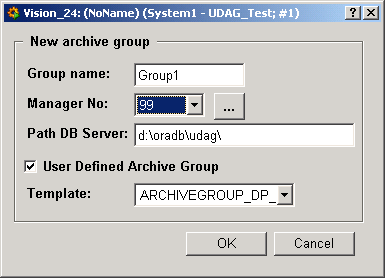
When you create a new archive group, you must input the group name, the manager number for the RDB Archive Manager that writes to this group and the path to the Oracle database (the path to where the archive group tablespaces is stored).
Click the ellipsis button to display the RDB Archive Manager main panel for selecting a manager and click the Use button to confirm your choice (see Setting parameters for the RDB Archive Manager). However, you can also configure a new RDB Manager and use this for the new archive group you are creating. Activate the check box "User defined Archive group" if you want to create an archive group according to your requirements and use the template for defining the archive group. See chapter User defined archive groups for more information.
If a created archive group already in the RDB database exists, so you can't create or modify it again. You have the possibility to create a new data point that specifies the structure of this archive table.
Configuration
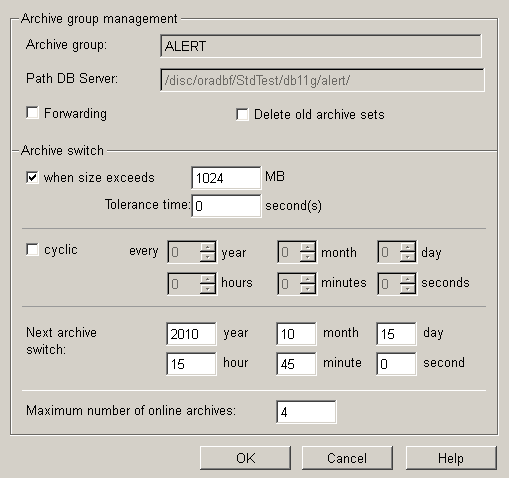
Setting the parameters of the archive group involves defining specific parameters for changing archive records and the scheduled times. Archive change in the RDB means the current table is closed and converted into an online table. Then a new current table is created (see Working principle of RDB archiving for further details on table structure in the RDB).
Archive group: Name (display) of the archive group.
Path DB Server: Path to the DB server.
Forwarding: Activates the forwarding of data to the central database in a distributed system (see also Oracle Synchronization).
Delete old archive sets: Careful, this is a delete instead of a backup. Archives, for which this checkbox has been activated, are not backed up if the maximum number of online archives is exceeded but are deleted instead. Deleted archives cannot be restored. This option makes sense when, for example, only temporary data that is not important in the long run, is saved in an archive.
Change archive: Setting that specifies whether to initiate an archive change. The size is specified in MBs. The size is calculated using the extent size (= Oracle Extents: the space, Oracle allocates for the data file).
Tolerance time: Time before and after a scheduled archive change during which no further archive change is performed if the size limit was exceeded.
cyclic: This check box enables or disables cyclic backup. If this option is enabled, you must also enter an interval (every...) at which to backup an archive.
If you check the check box "when size exceeds .. MB", the archive will be changed only after the current archive exceeds the configured size. If you check the check box "cyclic", a cyclic archive change will be executed. Thereby, enter the date of the first archive change manually. Enter the date to the field "Next archive switch". Start date of the option "cyclic"is the date that was configured for "Next archive switch". After the archive was changed, the panel shows when the next archive change will be executed. If a "Next archive switch" was not configured, an archive change will executed when the archive exceeds in this case the size 1024MB.
Next archive switch: Time of next scheduled archive change. You have to set the time manually at least once. This is the time for the first archive change. Thereafter, the date is calculated automatically. The time can, however, also be set manually (afterwards). In this case, the cycles are only continued after this archive set change (time).
Maximum number of online archives: Maximum number of online archives (if exceeded, the oldest online archive is backed up). Current archive and restored archives are not included in the count.
Historical (Oracle) Synchronization
The state panel of the Oracle Synchronization shows line by line the transmission state of a data set transmitted from the locale system to the central system and allows the switch to a manual synchronization (by default the automatic synchronization is turned on - this is executed in the background).
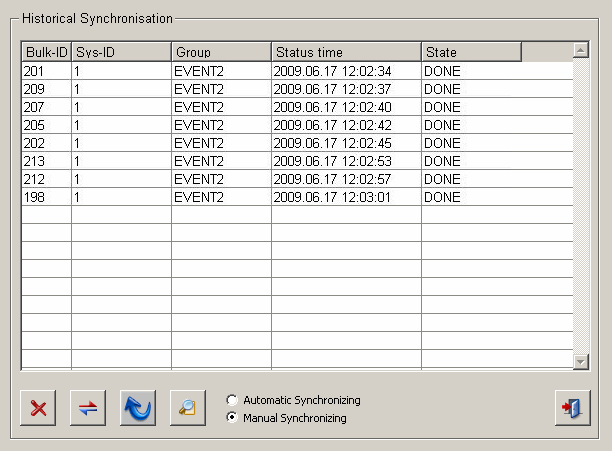
The table contains the following information:
- Bulk-ID - is needed for recovery in the case of failure and is - combined with the system-ID - globally unique.
- Sys-ID - specifies the system ID, which together with the bulk ID identifies the data set uniquely.
- Group - the archive group, whose data are transmitted
- Status time - status time of the data transmission.
-
State - the current state of the data set transmission. For possible states and their meaning see Status of the Synchronization.
With the aid of the radio boxes Automatic Synchronizing (default) and Manual Synchronizing beneath the table, it is possible to switch between the both transmission modes.
The buttons beneath the table have the following functions:
![]() - Deletes a selected data set row from the table. In case of an automatic synchronization this button is grayed out.
- Deletes a selected data set row from the table. In case of an automatic synchronization this button is grayed out.
![]() - Forwards the selected data set row to the central system. In case of an automatic synchronization this button is grayed out.
- Forwards the selected data set row to the central system. In case of an automatic synchronization this button is grayed out.
![]() - Updates the table.
- Updates the table.
![]() - Opens the filter panel for filtering the available state lines:
- Opens the filter panel for filtering the available state lines:
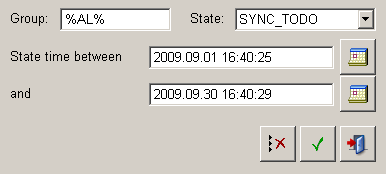
Group - filters for an archive group name or only a part of it (wildcards like % or * can be used).
State - filters for the current state.
State time between .. and - here click on the corresponding calendar symbol to open the calendar, which allows the date and time selection.
Activity
The archive overview serves two main purposes:
- Clear presentation of all archives
- Manual archive operations such as:
-
- Changing archives
- Restoring archives (set the offline archives online)
- Backing up archives (set the online archives offline, backup or delete them)
- Deleting archives
In the archive overview, the current and online archives are shown in the left table, the archived and backed up offline archives in the right table. The archives that can be restored (physically), meaning archives that were copied from tape to the backup path or archives but actually have not yet been moved from the backup path to the tape yet, are shown in bold type.
As long as an archive is visible in the table on the left or on the right it can be used. If it is backed up (shown on the right with the status offline) it has to be restored first through the button with the arrow pointing left and getting its status restored. If a current or online archive is no longer needed for reading, it can be moved to the right table by the arrow button with the right pointing arrow).
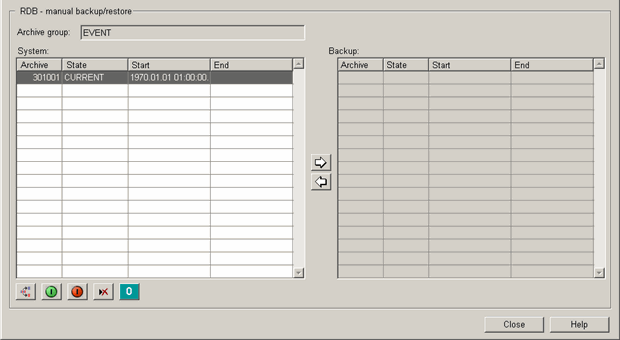
The panel shows the archives that are online, offline and already backed up. Archives that are already backed up can be restored again so that they can be accessed from WinCC OA. The following data is shown for each archive group:
- Archive number
- Status
- Start time
- End time
The manual operations can be controlled using the buttons in the bottom left corner of the panel and between the two tables.


![]() Change archive. A new archive has been created. The status of the archive is first new. Then it
becomes the new current archive and thus triggers a set of actions. The archive that has been current so far, is now set online. If the maximum number of online archives have been
exceeded, the oldest online archive is set offline and backed up or deleted.
Change archive. A new archive has been created. The status of the archive is first new. Then it
becomes the new current archive and thus triggers a set of actions. The archive that has been current so far, is now set online. If the maximum number of online archives have been
exceeded, the oldest online archive is set offline and backed up or deleted.
To be able to backup an archive, set the archive offline first so that the archive cannot be accessed any more by write or read operations.
![]() Set archive offline.
Set archive offline.
![]() With this button you can restore the status again after a backup has crashed.
With this button you can restore the status again after a backup has crashed.
![]() All selected archive sets with the status offline are backed up using the "Export selected file sets" button
.
All selected archive sets with the status offline are backed up using the "Export selected file sets" button
.
Manual backup
In order to be able to restore an archive it has to exist in the backup directory. For example, you want to access data with the compression level "One hour" and during the interval between 8:00 and 9:00 UTC on 09.07.06. In the figure above (Archive overview of archive group C1HOUR), you can see that two archives cover this interval, namely 21002 and 21005. Search the associated files for these intervals (on the tape) and copy them into the backup directory. Each backed up archive (when using the Oracle enterprise version) consist of two backup files: dump (*.dmp) containing the table space information and the data file (*.dbf or when compression is used *.zip) containing the table space data.
If an Oracle standard version is used, the file with the table space information (*.dmp) does not exist. Only the data files exist.
The following four files are necessary: (files that do not exist in the standard version are indicated by *):
1. C1HOUR_00021002_19700101010000_20050907070929.DMP*
2. C1HOUR_00021002_19700101010000_20050907070929.DBF
3. C1HOUR_00021005_20050907070930_20050907081556.DMP*
4. C1HOUR_00021005_20050907070930_20050907081556.DBF
These files must be copied into the backup directory before restoring (import) them. The import is initiated by clicking the button with the left pointing arrow.
![]() Import and restore datasets
Import and restore datasets
Set archive online
Offline archives can be set online again.
![]() Set archive online.
Set archive online.
Delete archives
Archives that are not needed anymore can be selected and deleted (with exception of the newest or "the most current" row).
![]() Delete selected backup file.
Delete selected backup file.
DB configuration
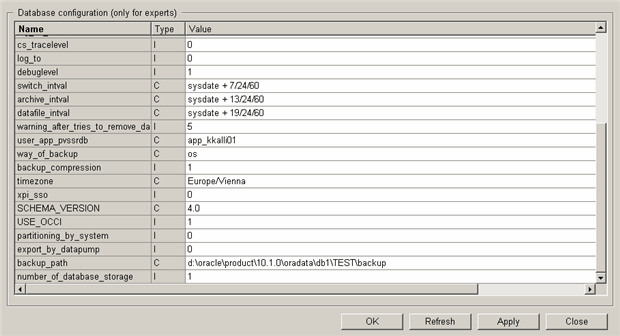
| Parameter | Description | Other occurence |
|---|---|---|
| SCHEMA_VERSION | RDB schema version. | |
| USE_OCCI | Is the OCCI interface used (1/0; recommended 1). | Setup: 'use_ooci' (yes/no), WinCC OA config: writeWithBulk (1/0) |
| archive_intval | The task for archiving (ArchiveMon). Starts cyclical. Define here the interval between the single starts (as the dbms_job requires. With 'sysdate + d' whereas d is the interval specified as days e.g. 'sysdate + 13/24/60', which starts the job every 13 minutes. | |
| backup_compression | Are the archives compressed after backup (1/0). | 'zip_backup' (yes/no) |
| backup_path | Backup path on the Oracle server (must end with a backslash "\" under Windows or with a slash "/" under Linux). | Setup: 'path_backup' |
| cs_tracelevel |
Control the tracing of statistical functions (possible values from 0 to 4), for ARC_LOG: 0 ... only errors, 2 ... Erros+Warning, 3 ... Also infos, for CS_TIMELOG: possible values 0-4, depending on how much information should be saved about the statistical calculation (statistical functions are not used at the moment). |
|
| datafile_intval | The task for deleting redundant database files (DataFileMon is only used under Windows). Starts cyclical. Define here the interval between the single starts (as the dbms_job requires. With 'sysdate + d' whereas d is the interval defined as days e.g. 'sysdate + 13/24/60', which starts the job every 19 minutes). | |
| debuglevel |
0 only errors and warnings (EW), 1 normal logging with infos (I), 2 logging with debugging (D), 3 logging with extra debugging (X) (possible values 0-3, default 1). |
|
| def_dbfile_path | Default path for the database files on the Oracle server (must end with a backslash "\" under Windows or with a slash "/" under Linux). The default setting is used by new groups if you do not define anything extra. | Setup: 'path_dbfile' |
| def_initial_size |
Default for the initial size of the table spaces in megabytes (schema tablespace, temporary tablespace, archive tablespaces) The default setting is used by new groups. |
'initial_size' |
| def_max_online |
Default for the number of archives that are maximum ONLINE before they are automatically updated (possible values from 0 upwards, default 4). The default setting is used by the new groups |
|
| def_max_size_mb |
Default for the maximum size of a CURRENT archive. When the value limit is exceeded the CURRENT archive is set ONLINE. The default setting is applied by the new groups. |
|
| def_max_size_of |
Default for the calculation of the maximum size (possible values: 'F'...calculation of the file size, 'E'...calculation of the extent size, 'X'...calculation of the file and extent size + the higher value is chosen). The default setting is applied by the new groups. |
|
| def_next_size | Default for the extent size of the table space in megabytes (schema tablespace, temporary tablespace, archive tablespaces). The default setting is used by the new groups. | Setup: 'next_size' |
| def_storage_clause | Memory clause for dynamic tables like e.g. EVENTHISTORY_12345678 in an archive (possible value: INITIAL 10M MINEXTENTS 1 MAXEXTENTS UNLIMITED') | Setup: 'storage_clause' |
| def_storage_clause_idx | Memory clause for dynamic tables for the indices of the dynamic tables in an archive (possible value: INITIAL 10M MINEXTENTS 1 MAXEXTENTS UNLIMITED') | Setup: 'storage_clause_idx' |
| forceDel_wait_hours | Minimum time before ForceDel is started (efault 12). | |
| forceDel_wait_tries | Minimum number of unsuccessful deletion attempts before ForceDel is used. If the entry is 0, ForceDel is never used (Default 0). | |
| log_duration | Duration for how long (in days) LogEntries should be kept in the Tables ARC_LOG, CSTIMELOG or JAVA_LOG. Default: 60 (i.e. a LogEntry will be deleted after 60 days) | |
| log_os_cmd | Logging when system calls or Java procedures are executed (possible values 0/1, default 1). The logs are located either in the temp directory, in the backup directory or in the JAVA_LOG table (depending on the logged action and the Java setting). | |
| log_to | Specifies where the logging information should be saved: In the table ARC_LOG (value 0 or 2) or in the file RDB_debug.log (value 1 or 2). The value should always be 0 (except for justified exceptional cases). Possible values 0/1/2. The default and recommended value is 0. | |
| number_of_database_storage | Number of database storages (normal case 1 e.g. in case of single databases, RAC and Fail-Safe. Only in case of DataGuard > 1). | Setup 'number_db_storage' |
| partitioning_by_system | Configuration of the dynamic archive tables on the basis of the SYS_ID (1/0). | Setup: 'sys_partitions' (yes/no) |
| path_oraclebin | Path to the Oracle bin directory (must end with a backslash "\" under Windows or with a slash "/" under Linux). The path is required for different program functions. | Setup: 'path_oraclebin' |
| prog_chmod_exec |
Required for Linux with the option Java: path + program name + 1. Parameters for chmod, e.g. '/bin/chmod 777' |
|
| prog_systemcopy |
Required for the option Java: path + program for copying, e.g.: 'cmd /c copy' for Windows or '/bin/cp' for Linux |
|
| prog_systemunzip |
Required for the parameter java="yes". Unzipping via: /usr/bin/unzip -oj <zipfile> -d <destdir> |
|
| prog_systemzip |
Required for the parameter java="yes". Zipping via: /usr/bin/zip -j <zipfile> <sourcedir> A verification whether the backup (zip or copy) was successful takes place. If the Oracle program zip.exe is used (default) the outsourced database files must not exceed the size of 4GB. Otherwise zipping fails. |
|
| pwd_backup |
Parameter only for compatibility reasons: encrypted password for the user to backup and restore. Default NULL. |
|
| switch_intval | The task for the archive switch (SwitchMon). Starts cyclical. Define here the interval between single starts (as the dbms_job requires. With 'sysdate + d', whereas d is the interval defined as days e.g. 'sysdate + 7/24/60', which starts the job every 7 minutes). | |
| timezone | Local time zone (see v$timezone_names e.g. 'Europe/Vienna'). Is required internal for different time calculations. | Setup: 'mytimezone' |
| user_app_pvssrdb | Application User as given in the setup. In exceptional cases the value may be 'PUBLIC'. The value may be 'PUBLIC' when the rights were not defined for an application user but are public (depending on 'public_grants'). | Setup: combination of '&app_user' and 'public_grants' |
| waitForRMANFileSec |
Parameter for RMAN backup. While <waitForRMANFileSec> seconds, the progress (% done) of the backup must raise. If not, the backup is canceled, since it is assumed that an error has occurred. Default = 300 seconds (= 5 minutes). |
Setup: 'use_rman' |
| warning_after_tries_to_remove_datafile | Number of unsuccessful deletion attempts which are not logged in order not to overflow the log. When the value limit is exceeded, each unsuccessful attempt is written into the log (default is 7). | |
| way_of_backup | How is the backup executed: either via tablespace export (os) or via Oracle's RMAN (rman). | Setup: 'use_rman' |
| xpi_sso | Is not supported anymore. The value must be 0. |
How to use ForceDel.exe (if Oracle database files remain locked)
Each archive group has a directory where the database creates the tablespace files. You define the directory when you create the archive group or the database uses the default directory ARC_CONFIG ('def_dbfile_path') (see the figure "RDB configuration parameters" and the description of parameters above) .
Sometimes the data files of already deleted Oracle tablespaces remain locked by Windows for some time even after the corresponding tablespace was dropped (Windows System Error 32). Sometimes the lock takes a day or more.
ForceDel is able to delete files even if they are still locked. This is very useful if you cannot, for example, wait for the files to be released, due to harddisk capacity etc. However, it has to be used very carefully in order to not delete files which are still needed. In such a case, Oracle could crash and restarting difficult.
When the ForceDel deletes a file successfully, you cannot find the archive with a specific archive number, for example, <username>_EVENT_12345678.dbf anymore.
ForceDel can only be used with the Java version ("use_java: yes").
You can obtain ForceDel.exe from either of the following:
http://www.codeguru.com/Cpp/W-P/files/fileio/article.php/c1287/
or
http://www.technipages.com/modules.php?name=Downloads&d_op=viewdownloaddetails&lid=32&title=ForceDel
ForceDel is only for Windows systems and has to be copied into the Oracle BIN directory (for example, D:\oracle\product\10.2.0\DB_1\BIN) and the Oracle-BIN directory has to be correctly entered during the setup (configuration parameter "path_oraclebin").
ForceDel information:
ForceDel is freeware written by Zoltan Csizmadia, zoltan_csizmadia@yahoo.com
There are two parameters that control the execution of ForceDel in the table ARC_CONFIG (accessible from the WinCC OA panel "Configuration settings" shown in the figure "RDB configuration parameters" above):
-
forceDel_wait_tries: This parameter indicates the number of tries to delete a file "normally" (waiting thus until Windows removes the lock) before ForceDel is used.
If the value is 0 (default), ForceDel is not used.
Numbers greater than 0 activate ForceDel.
Note: Choose a number big enough (for example, 50) to give Oracle enough time to "redraw". Otherwise problems can occur if Oracle somehow still uses the file.
-
forceDel_wait_hours: Sets the minimum time in hours before ForceDel is used for the first time. In this way, even when the forceDel_wait_tries stage has been reached, ForceDel waits until the specified hours have passed before acting.
The default time is 12 hours. This allows approximately 38 wait tries with the default DataFileMon cycle.
Site configuration
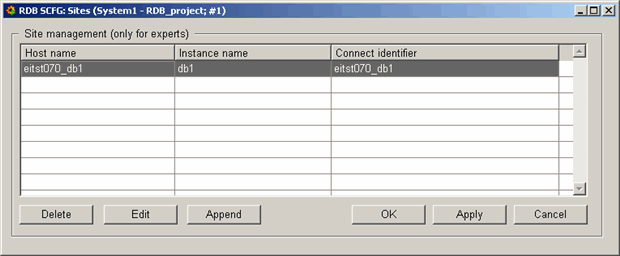
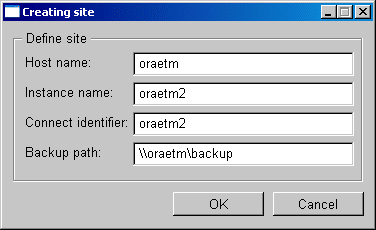
This panel is used to create and configure an RDB site. A site is a computer on which the RDB database replicates the data (the "actual" database server is also called a site). This allows the option of backing up data (comparable with redundancy in WinCC OA). When you create a new site, you must input the host name of the site, the instance name (name of the database) and the connect identifier.
Note that for a RAC, only one entry per cluster is needed. If a cluster (for example, RAC) is available, you need to insert only one entry (You can of course also enter each instance separately). For the configuration consider that the databases can be accessed through the specified Connect identifier irrespective of which instance is running on the cluster. Host can in this case be left empty.
With DataGuard (or when several physical databases are running), the host has to be entered so that the passive paths can be found.
Archives are only backed up to a backup drive for the active site. Passive (standby) sites simply delete the specified offline archives.



