Prinzip und Funktionsweise
Im Normalfall besteht ein redundantes System aus zwei Projekten auf unterschiedlichen Rechnern mit gleichem Betriebssystem. Auf diesen beiden Systemen, die untereinander mit einer redundanten Netzwerkverbindung ausgestattet sind, laufen dieselben Manager. Die Redundanz an sich bleibt den Managern großteils verborgen, d.h. sie verhalten sich wie in einem einfachen System. Tatsächlich werden Datenstrom und Dynamik über System Messages des Event-Managers kontrolliert und gesteuert.
In einem redundanten System können einzelne Systemkomponenten überwacht und mit einer Gewichtung versehen werden, die im Fehlerfall zur Berechnung des Fehlerstatus dient. Solche
Komponenten, die überwacht und zur Berechnung des Fehlerstatus herangezogen werden, sind zum Beispiel: Manager, TCP-Verbindungen, SPS-Verbindungen, Festplattenkapazität, RAM-Speicher usw.
Die Gewichtung ist eine Nummer von 0-999, die der Benutzer bei der Parametrierung spezifisch für die Komponenten vergeben kann. Die Entscheidung wie schwerwiegend ein Fehlerfall ist, d.h.
welche Nummer für die Gewichtung eingestellt wird, trifft der Anlagenbetreiber bzw. Integrator. Der Ausfall einer Verbindung zur SPS wird z.B. mit einer höheren Gewichtung parametriert als
der Ausfall eines UIs. Im Normalfall sollte die Summe der Gewichtungen, die den Fehlerstatus ergeben, auf beiden Rechnern gleich sein (optimal ist Fehlerstatus 0). Im Fehlerfall erfolgt
eine automatische Umschaltung, d.h. der aktive Rechner ist immer der Rechner mit dem geringeren Fehlerstatus. Die Fehlerberechnung selbst findet im CONTROL-Skript
calculateState.ctl statt (dieses Skript ist in der pvss_scripts-Liste enthalten). Die Parametrierung der Fehlergewichtung wird im
Systemübersichtspanel vorgenommen. Für weitere Informationen siehe Panel Systemübersicht
bei Redundanz.
Weitere wichtige Funktionen übernimmt der Redu-Manager (WCCILredu) im Falle eines redundanten Systems (die Defaultportnummer des Redu-Managers ist 4776). Der Redu-Manager hat folgende Aufgaben:
- Ableitung des Redundanzstatus: Der Redundanzstatus (welcher Rechner ist gerade aktiv und welcher passiv) wird vom Redu-Manager bestimmt und vorgegeben, da dieser alle Informationen (interne Systemzustände) von sich und seinem Partner hält. Darüber hinaus verwaltet er die Fehlerstati von sich und seinem Partner. Diese Stati werden miteinander verglichen und es wird automatisch der Rechner mit dem kleineren Fehlerstatus aktiv (die Umschaltung des aktiv/passiv Zustandes der Rechner wird vom Event-Manager ausgeführt).
- Austausch von Systeminformationen und Alive Telegrammen
- Auswertung von Partnerausfällen
Um das Prinzip der Redundanz ein wenig besser zu veranschaulichen, soll folgende Grafik dienen:
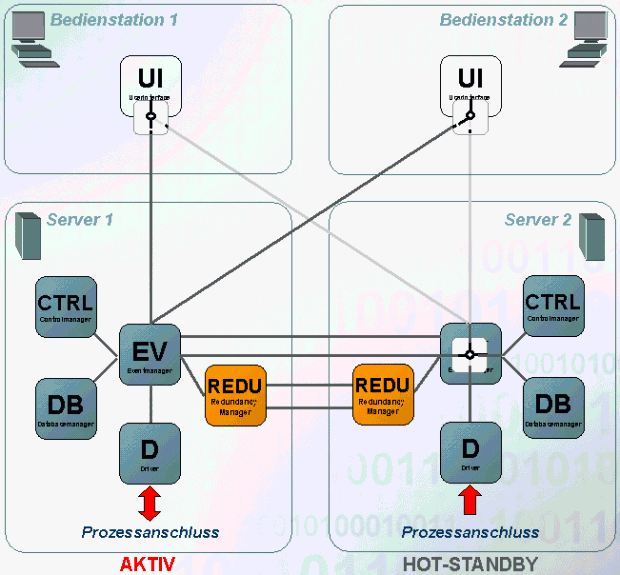
Die Abbildung zeigt eine detaillierte Darstellung der beiden Rechner Server 1 und Server 2, wie sie bereits aus der Abbildung auf der Seite Grundlagen Redundanz bekannt sind. Server 1 befindet sich im Führungsmodus (aktiv) und Server 2 ist im Hot-Standby-Modus (passiv).
Die UIs beider Bedienstationen sind im Redundanzfall mit beiden Event-Managern verbunden, es werden jedoch nur die Daten des aktiven Systems auf beiden UIs dargestellt.
Der Event-Manager des passiven Systems beschränkt sich rein auf die Kommunikation mit dem Event-Manager des aktiven Systems zum Abgleich der Prozessdaten (er schickt keine Daten an die verbundenen UIs bzw. verwirft Meldungen von den Treibern - dies ist in der Abbildung mit den Weichen bei den UIs bzw. beim passiven Event-Manager ersichtlich). Nachrichten die der Event-Manager durch das aktive System erhält werden an die entsprechenden lokalen CTRL Manager und Treiber gesendet. Die Treiber verwerfen diese Befehle an die SPS jedoch wieder.
Die Telegrammlauflogik (Meldungen und Befehle) wird anhand der nachfolgenden Abbildungen näher erläutert.
Treibermeldung
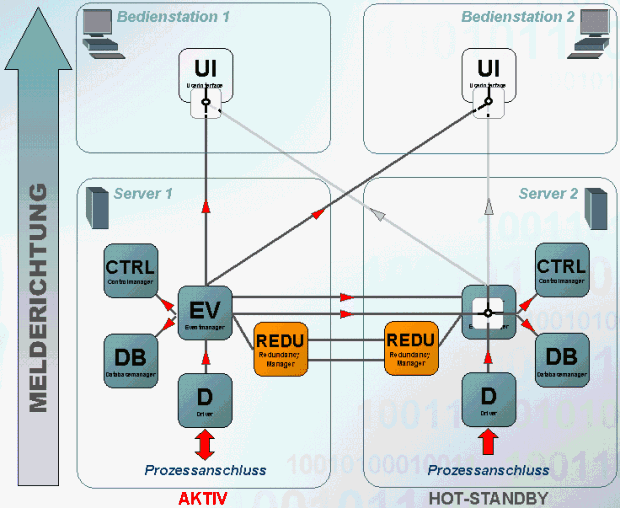
Die Verarbeitung eines Telegramms in Melderichtung erfolgt auf folgendem Weg:
- Beide Treiber bekommen eine Meldung von der Peripherie (dieser Fall trifft nicht immer zu, da bei Parametrierung eines Pollings, unterschiedliche Werte zu unterschiedlichen Zeiten beim Treiber ankommen, d.h. nur auf einem Rechner bekommt der Treiber eine Meldung). Am aktiven System wird der Wert an den Event-Manager weitergereicht, das passive System verwirft die Meldung.
- Der Event-Manager am aktiven System schickt den Wert an alle angemeldeten Manager. Über die redundante Netzwerkverbindung wird der Wert an den passiven Event-Manager geschickt. Am passiven System wird wiederum der Wert an alle beim Event angemeldeten Manager weitergeschickt.
- Der Wert wird an die UIs beider Bedienstationen nur vom aktiven Event geschickt.
Treiberbefehl
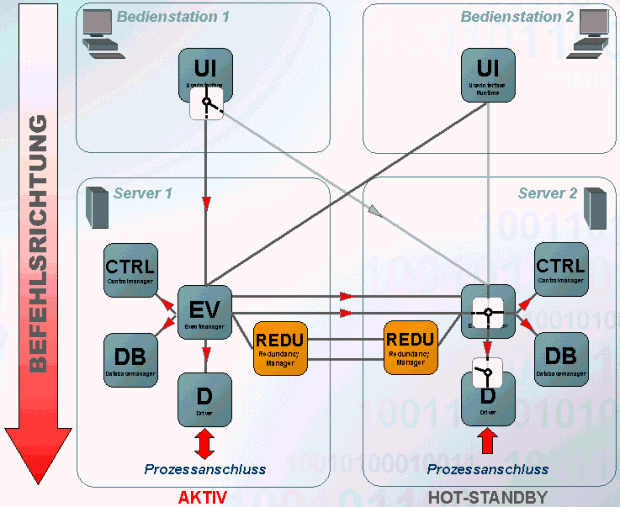
Die Verarbeitung eines Telegramms in Befehlsrichtung erfolgt auf folgendem Weg:
- Auf dem UI der Bedienstation 1 findet eine Wertänderung statt. Die Änderung wird an den Event-Manager des aktiven Systems geschickt, der passive Event-Manager akzeptiert keine Änderung vom UI.
- Der Event-Manager am aktiven System schickt den Wert an alle angemeldeten Manager. Über die redundante Netzwerkverbindung wird der Wert an den passiven Event-Manager geschickt. Am passiven System wird wiederum der Wert an alle beim Event angemeldeten Manager weitergeschickt.
- Die Wertänderung wird über den Treiber am aktiven System an die Peripherie weitergereicht. Der Treiber am passiven System verwirft die Wertänderung und leitet keine Daten an die Peripherie weiter.
Da die Datenbank auf beiden Rechnern identisch ist, existieren auf beiden Rechnern dieselben DPs. Diese DPs haben immer den gleichen Wert und Namen auf beiden Rechnern. Für die bisher beschriebenen DPs (in Befehls- bzw. Melderichtung) ist dies so gewünscht. Das Verhalten der Telegrammlauflogik in Melde- sowie Befehlsrichtung wurde bereits in den vorangegangen Absätzen erklärt.
Des Weiteren gibt es Datenpunktelemente für interne Zustände (z.B. Plattenplatz, RAM Speicher, Verbindung zur Peripherie, ...), deren Information auf beiden Rechnern unterschiedlich sein kann und auch auf beiden Rechnern bekannt sein muss. Dieser Fall wird im Redundanzbetrieb anders gelöst:
- DPs, die für interne Zustände die Informationen halten, existieren zweimal mit unterschiedlichen Namen (einmal mit dem Postfix "_2" und einmal ohne Postfix) auf jedem Rechner.
- Der linke Rechner ist für den Datenpunkt ohne Postfix zuständig, der rechte Rechner setzt den "_2" Datenpunkt. Angenommen der S7-Treiber verliert die Verbindung zur Peripherie, so würde im Falle der normalen Telegrammlauflogik (linker Rechner ist aktiv, rechter Rechner ist passiv) das Element _S7_Conn.ConnState am linken Rechner gesetzt. Würde der Verbindungsverlust am rechten Rechner eintreten, so verwirft dieser den Wert (da ja passiv) und der "_2" Datenpunkt wird nicht gesetzt. Damit ein solches Verhalten nicht eintritt, gibt es sogenannte "Forward DPs". Forward DPs werden gesetzt und zum anderen Rechner übertragen (das DPE _S7_Conn.ConnState ist ein solcher Forward DP). Damit ist gewährleistet, dass immer gleichzeitig auf beiden Rechnern beide Informationen verfügbar sind.
- Der Datenpunkt _S7_Conn besteht jedoch nicht nur aus dem Element .ConnState, sondern auch aus Elementen, die Parametrierungen enthalten bzw. Befehle auslösen (z.B. _S7_Conn.DoGeneralQuery, _S7_Conn.UseTSPP, _S7_Conn.ProjectName, ...). Der Wert dieser DPEs muss im Normalfall am linken und rechten Rechnern ident sein. Damit solche DPEs auf beiden Rechnern gleich sind, gibt es sogenannte "Copy DPs". Copy DPs übernehmen den gesetzten Wert auf die DPEs der beiden Rechner, also wenn z.B. das Element _S7_Conn.UseTSPP auf den Wert "1" gesetzt wird, wird automatisch der Wert "1" auch am Element _S7_Conn_2.UseTSPP gesetzt.
Einstellungen bezüglich Forward und Copy DPs (speziell bei projektspezifischen Anpassungen) werden in der Konfigurationsdatei config.redu im Verzeichnis
<proj_path>/config (siehe auch Konfigurationsdateien für die Redundanz) vorgenommen.
Mit dem Schlüsselwort "fwdDpType" (analog zu fwdDp) werden alle Änderungen an diesem DP-Element vom Event-Manager automatisch an den redundanten Event-Manager weitergeleitet. Im Unterschied zu "fwdDp" wird nicht ein DP-Element eines existierenden Datenpunktes angegeben, sondern das Element eines DP-Typs in der Form "Typ.Element" (z.B. "ExampleDP_Bit." für das Rootelement des DP-Typs "ExampleDP_Bit"). Es werden also die entsprechenden Elemente aller Datenpunkte von diesem Typ weitergeleitet.
Split-Betrieb bei Redundanz
Der Split-Betrieb bei redundanten Systemen ist eine Trennung der beiden redundanten Server, wobei ein Server aktiv bleibt. Der zweite Server kann für Tests von neuen Konfigurationen und Parametrierungen verwendet werden. Der Vorteil besteht darin, dass dies im laufenden Betrieb auf einer Anlage gemacht werden kann, ohne jegliche Beeinträchtigung für das aktive System.
Bei Verwendung des Split-Betriebs kann frei gewählt werden, welches System aktiv bleibt (Umschaltung der UIs auf dieses System) und welches System für Testzwecke verwendet wird. Nach dem Beenden der Tests erfolgt eine automatische Rückführung in den Redundanz-Betrieb auf Basis eines Systems. D.h. ist der Test erfolgreich verlaufen, wird durch die Rückführung in die Redundanz mit einem Recovery das Führungssystem abgeglichen und die neue Konfiguration wird auf beiden Systemen verwendet. Soll das alte System weiter im Redundanz-Betrieb laufen, wird das Testsystem mit dem Führungssystem abgeglichen und der redundante Betrieb auf der Anlage läuft mit den Einstellungen, wie sie auch vor dem Wechsel in den Split-Betrieb existiert haben.
Nähere Informationen zum Split-Betrieb erfahren Sie auf den Seiten Panel Systemübersicht bei Redundanz und Redundanz im Split-Betrieb.
Redundanz-Verhalten des passiven Events
Das in WinCC OA eingesetzte Redundanz-Verhalten sorgt dafür, dass die Wertänderungen im passiven Event nicht eher verworfen werden, bis sichergestellt wird, dass der aktive Event diese verarbeitet/weitergeleitet hat.
Gut-Fall
Zeitstempel Event-Manager (1|2) Beschreibung
----------------------------------------------------------------------------------
10:00:00 Event 1(aktiv) Bekommt Wertänderung 1
10:00:01 Event 2 (passiv) Bekommt Wertänderung 1 und wartet auf Wertänderung durch Server 1
10:00:03 Event 1(aktiv) Verarbeitet Wertänderung 1 und leitet sie an den Event 2
10:00:22 Event 2 (passiv) Verwirft gepufferte Wertänderung 1Kritischer Fall - Ausfall des aktiven Events:
Zeitstempel Event-Manager (1|2) Beschreibung
----------------------------------------------------------------------------------
10:30:00 Event 1 (aktiv) Bekommt Wertänderung 2
10:30:01 Event 2 (passiv) Bekommt Wertänderung 2 und wartet auf Wertänderung durch Server 1
10:30:03 Event 1 (aktiv) Fällt aus -> keine Weiterleitung an den passiven Event!
10:30:13 Event 2 (passiv) Erkennt den Ausfall des aktiven Events, wird zum aktiven und verarbeitet alle Wertänderungen, die noch nicht verarbeitet wurden
10:30:14 Event 2 (jetzt aktiv) Verarbeitet gepufferte Wertänderung 2Zeitunterschiede zwischen Redu-Partnern
Durch Verwendung von valueChangeTimeDiff überprüft der jeweilige Manager die Zeitdifferenz zwischen dem Redu-Partner. Das Ergebnis wird auf den verbindungsspezifischen Datenpunkt _ManagerConnections.TimeDiff geschrieben. Bei Überschreiten der Grenze der Zeitdifferenz wird die Verbindung durch den Manager beendet und eine entsprechende Meldung im LogViewer ausgegeben.



